
 349
349


Вчені розробили новаторський метод, щоб виявити, як глибокі нейронні мережі «мислять», нарешті проливаючи світло на їхній процес прийняття рішень. Завдяки візуалізації того, як штучний інтелект організовує дані за категоріями, цей метод забезпечує безпечніший і надійніший штучний інтелект для таких реальних додатків, як охорона здоров’я та безпілотні автомобілі, що робить нас на крок ближче до справжнього розуміння штучного інтелекту .
Розуміння рівнів обробки AI
Глибокі нейронні мережі — це тип штучного інтелекту (ШІ), призначений для імітації того, як людський мозок обробляє інформацію. Однак зрозуміти, як ці мережі приймають рішення, давно було складним завданням. Дослідники з Університету Кюсю розробили новий метод, щоб краще зрозуміти, як глибокі нейронні мережі інтерпретують дані та впорядковують їх у категорії. Їх висновки, опубліковані в IEEE Transactions on Neural Networks and Learning Systems, спрямовані на підвищення точності, надійності та безпеки ШІ.
Подібно до того, як люди крок за кроком вирішують головоломки, глибокі нейронні мережі обробляють інформацію на кількох рівнях. Перший рівень, який називається вхідним, збирає необроблені дані. Наступні рівні, відомі як приховані, аналізують дані поетапно. Ранні приховані шари виявляють прості елементи, як-от краї чи текстури, подібно до ідентифікації окремих частин головоломки. Глибші шари поєднують ці функції, щоб розпізнавати складніші візерунки, такі як розрізнення кота та собаки, подібно до збирання шматочків пазла, щоб сформувати повне зображення.
Прозорість у процесі прийняття рішень ШІ
«Однак ці приховані шари схожі на замкнену чорну скриньку: ми бачимо вхід і вихід, але незрозуміло, що відбувається всередині», — говорить Данило Васконселлос Варгас, доцент факультету інформатики та електротехніки Університету Кюсю. «Ця відсутність прозорості стає серйозною проблемою, коли штучний інтелект робить помилки, іноді викликані чимось таким незначним, як зміна одного пікселя. ШІ може здатися розумним, але розуміння того, як він приймає рішення, є ключовим для забезпечення його надійності».
Обмеження поточних методів візуалізації
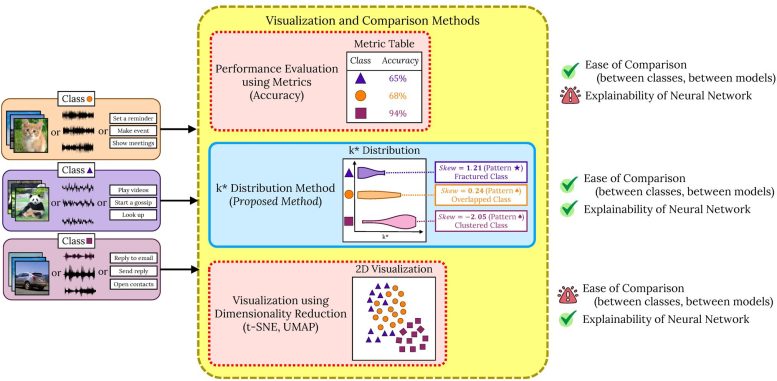
Наразі методи візуалізації того, як штучний інтелект організовує інформацію, ґрунтуються на спрощенні багатовимірних даних у 2D або 3D представленнях. Ці методи дозволяють дослідникам спостерігати, як штучний інтелект класифікує точки даних, наприклад, групуючи зображення котів поруч з іншими котами, відокремлюючи їх від собак. Однак це спрощення супроводжується критичними обмеженнями.
«Коли ми спрощуємо багатовимірну інформацію до меншої кількості вимірів, це схоже на зведення 3D-об’єкта до 2D — ми втрачаємо важливі деталі та не можемо побачити картину в цілому. Крім того, цей метод візуалізації того, як дані групуються, ускладнює порівняння між різними нейронними мережами або класами даних», — пояснює Варгас.
Представляємо метод розподілу k*
У цьому дослідженні дослідники розробили новий метод, який називається методом розподілу k*, який більш чітко візуалізує та оцінює, наскільки добре глибокі нейронні мережі класифікують пов’язані елементи разом.
Модель працює, призначаючи кожній введеній точці даних значення «k*», яке вказує відстань до найближчої непов’язаної точки даних. Високе значення k* означає, що точка даних добре відокремлена (наприклад, кіт знаходиться далеко від будь-яких собак), тоді як низьке значення k* передбачає потенційне перекриття (наприклад, собака ближче до кішки, ніж інші коти). При перегляді всіх точок даних у класі, наприклад котів, цей підхід дає розподіл значень k*, що дає детальну картину того, як організовані дані.
«Наш метод зберігає більший вимірний простір, тому інформація не втрачається. Це перша і єдина модель, яка може дати точне уявлення про «локальне сусідство» навколо кожної точки даних», — підкреслює Варгас.
Вплив і застосування нового методу
Використовуючи свій метод, дослідники виявили, що глибокі нейронні мережі сортують дані в кластеризовані, фрагментовані або перекриваючі механізми. У кластерному розташуванні подібні елементи (наприклад, коти) згруповані тісно разом, тоді як непов’язані елементи (наприклад, собаки) чітко відокремлені, що означає, що штучний інтелект може добре сортувати дані. Однак роздроблені розташування вказують на те, що подібні елементи розкидані на великому просторі, тоді як розподіли, що накладаються, виникають, коли непов’язані елементи знаходяться в одному просторі, причому обидва розташування роблять помилки класифікації більш імовірними.
Варгас порівнює це зі складською системою: «На добре організованому складі подібні предмети зберігаються разом, що робить пошук простим і ефективним. Якщо предмети змішані, їх стає важче знайти, що збільшує ризик вибору неправильного предмета».
ШІ в критично важливих системах і майбутньому
ШІ все частіше використовується в критично важливих системах, таких як автономні транспортні засоби та медична діагностика, де точність і надійність є важливими. Метод розподілу k* допомагає дослідникам і навіть законодавцям оцінювати, як штучний інтелект організовує та класифікує інформацію, виявляючи потенційні недоліки чи помилки. Це не тільки підтримує процеси легалізації, необхідні для безпечної інтеграції штучного інтелекту в повсякденне життя, але також пропонує цінну інформацію про те, як штучний інтелект «мислить». Виявляючи основні причини помилок, дослідники можуть удосконалити системи штучного інтелекту, щоб зробити їх не тільки точними, але й надійними — здатними обробляти розмиті або неповні дані та адаптуватися до неочікуваних умов.
«Наша кінцева мета — створити системи штучного інтелекту, які зберігають точність і надійність, навіть коли стикаються з проблемами реальних сценаріїв», — підсумовує Варгас.





